On The Silent Truncator: Debugging LinkedIn's UGC API
Discovering how text formatting and LinkedIn's ASCII parser can trigger silent rendering failures on the UI with limited to no descriptive error messages.

A major component of my automated pipeline is a custom Content Management System (CMS) hook that seamlessly extracts formatted posts and publishes them directly to LinkedIn using their /rest/posts API. The initial pipeline was solid: it transformed Rich Text into clean Unicode equivalents (learn more about Unicode from https://www.compart.com/en/unicode/ ) and handled multiple images flawlessly.
Why labour to transform Rich Text into Unicode?
Because LinkedIn's API strips away all formatting from the Payload CMS when parsing it. LinkedIn's API is developed using java, hence the Unicode will render on the LinkedIn Post UI.
However, an obscure bug surfaced that sent me down a deep rabbit hole: my posts were being silently truncated upon publication.
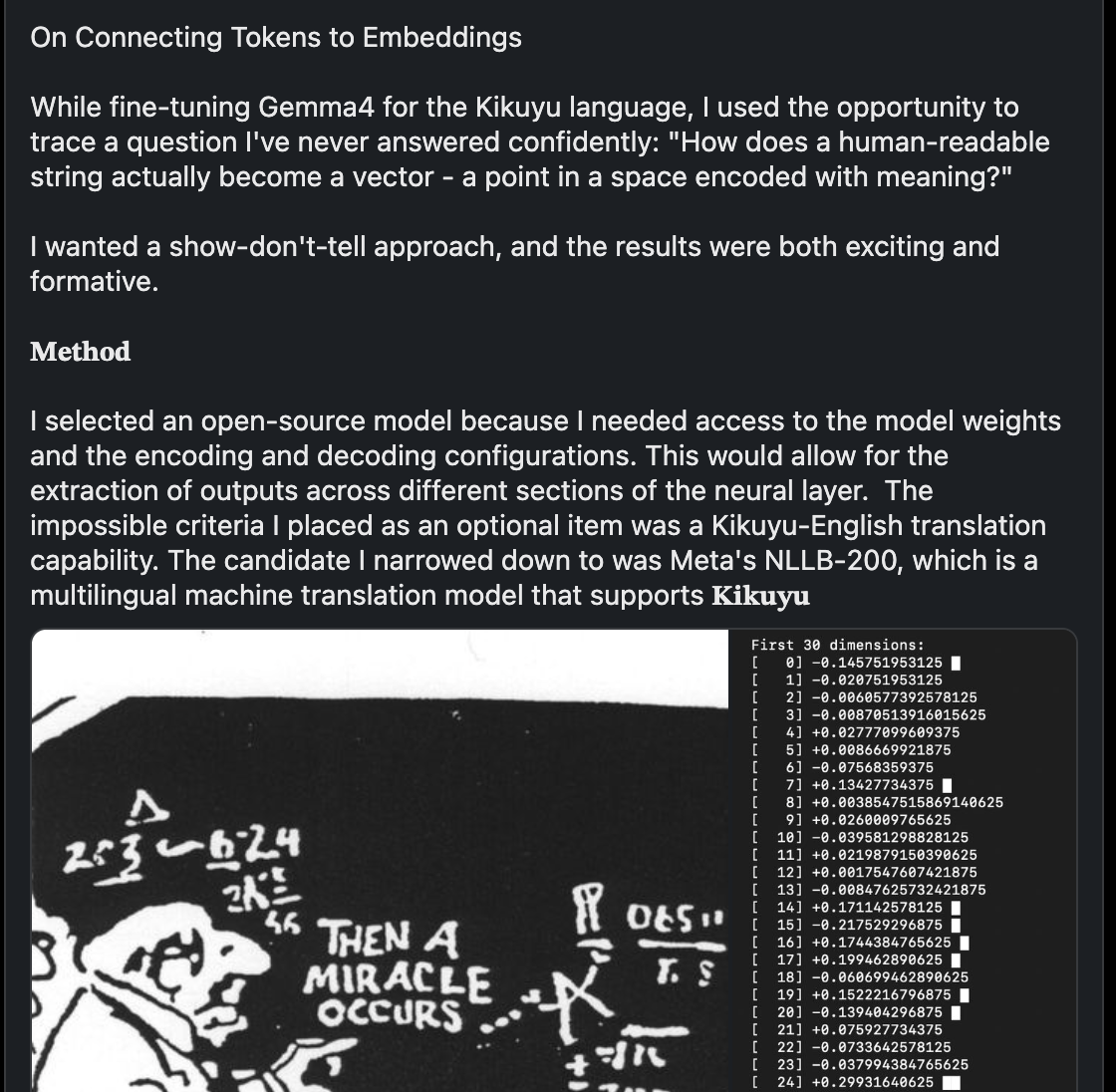
Iteration 1: The Invisible Characters & Budgeting
The most glaring symptom of the bug was that the concluding suffix, "... click the link to read more", alongside the portfolio URL and hashtags, was consistently missing from published posts.
My immediate hypothesis was straightforward character limit mismanagement. LinkedIn sets a strict 3,000-character ceiling for the commentary field. Since I was applying Unicode Mathematical Sans-Serif characters to emulate bold and italic typography, I assumed the CMS truncation algorithm was splitting multi-byte characters (surrogate pairs) or miscounting the budget.
The Fix:
I rebuilt the truncation logic to be code-point aware, ensuring surrogate pairs were never broken, and ultimately switched the entire budgeting system to use UTF-8 byte arrays (`TextEncoder().encode(s).length`).
The Result:
The local container logs confirmed the CMS was successfully building perfect payloads. The length was meticulously checked and mathematically verified to be well under the limit (e.g., 2,461 bytes). The API returned a triumphant `201 Created` with a valid Post URN.
Yet, when I opened LinkedIn, the text was still abruptly sliced off.
Iteration 2: The Parenthesis Theory
When comparing the logs with the live feed, a subtle pattern emerged. The truncation wasn't happening at a specific length limit—it was happening at specific characters.
One of my test posts ended exactly at the word `𝗞𝗶𝗸𝘂𝘆𝘂`. In my original text, that word was immediately followed by ` (𝗸𝗶𝗸_𝗟𝗮𝘁𝗻)`. The truncation occurred right at the space before the open parenthesis.
I suspected that the URL auto-linker was to blame. At the time, URLs were appended using parentheses: `text (url)`. Could the combination of special Unicode characters and parentheses be breaking the payload?
The Fix:
I modified the Lexical extractor to format links differently, completely avoiding parentheses in the auto-linker.
The Result:
The issue persisted.
Iteration 3: The Markdown Mention Parser
At this point, it became clear this wasn't a payload formatting error on my end, but a silent failure on LinkedIn's backend.
LinkedIn's internal text processor includes a parser that aggressively looks for mentions and hashtags (`@[Name](urn:li:person...)` or `{mention: urn...}`). This parser relies heavily on ASCII punctuation like `()`, `[]`, and `<>`.
When LinkedIn's backend Java regex engine encountered an ASCII parenthesis immediately succeeding (or containing) supplementary characters—like my U+1D5FA Mathematical Bold `𝗸`—the regex parser tripped over the surrogate pair boundaries. Rather than returning a helpful `400 Bad Request` or logging a visible error, the backend swallowed the exception, silently dropped the rest of the unparsed string, and published the surviving fragment.
The Full-Width Evasion
The fix required outsmarting the backend parser without sacrificing the visual typography of the post.
Since the bug was strictly triggered by the backend parser locking onto ASCII boundary characters, the solution was a systematic evasion strategy. At the absolute final stage of payload construction—just before calculating the byte-length budget—I implemented a global replacement function.
typescriptconst safeTitle = title .replace(/\(/g, '(').replace(/\)/g, ')') .replace(/\[/g, '[').replace(/\]/g, ']') .replace(/</g, '<').replace(/>/g, '>')
let safeBody = (bodyText ?? '') .trim() .replace(/\(/g, '(').replace(/\)/g, ')') .replace(/\[/g, '[').replace(/\]/g, ']') .replace(/</g, '<').replace(/>/g, '>')
I swapped all ASCII parentheses, brackets, and angle brackets with their fullwidth Unicode equivalents (e.g., `U+FF08` and `U+FF09`).
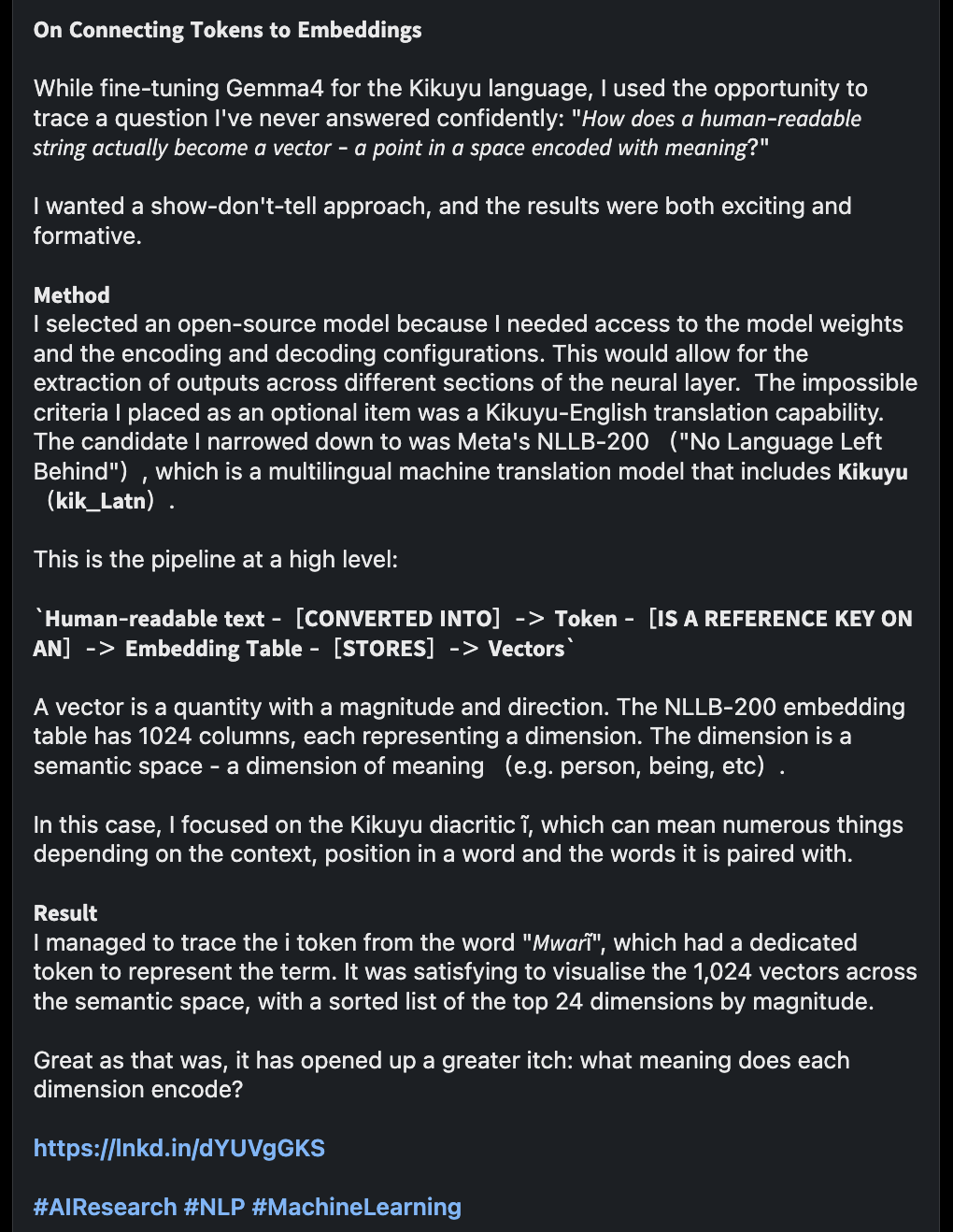
Visually, they are virtually indistinguishable to the human eye, providing the same reading experience. Programmatically, they are entirely ignored by LinkedIn's backend mention parser. The API swallowed the text whole, the bug was bypassed, and the posts finally published perfectly intact: URLs, hashtags, and all. Iterative debugging at its finest.