On Connecting Tokens to Embeddings
Tracing and visualising the encoding of human-readable text into embeddings that are consumable by a neural network.

While fine-tuning Gemma4 for the Kikuyu language, I used the opportunity to trace a question I've never answered confidently: "How does a human-readable string actually become a vector - a point in a space encoded with meaning?"
I wanted a show-don't-tell approach, and the results were both exciting and formative.
Method
I selected an open-source model because I needed access to the model weights and the encoding and decoding configurations. This would allow for the extraction of outputs across different sections of the neural layer. The impossible criteria I placed as an optional item was a Kikuyu-English translation capability. The candidate I narrowed down to was Meta's NLLB-200 ("No Language Left Behind"), which is a multilingual machine translation model that includes Kikuyu (kik_Latn).
This is the pipeline at a high level:
Human-readable text -[CONVERTED INTO]-> Token -[IS A REFERENCE KEY ON AN]-> Embedding Table -[STORES]-> Vectors
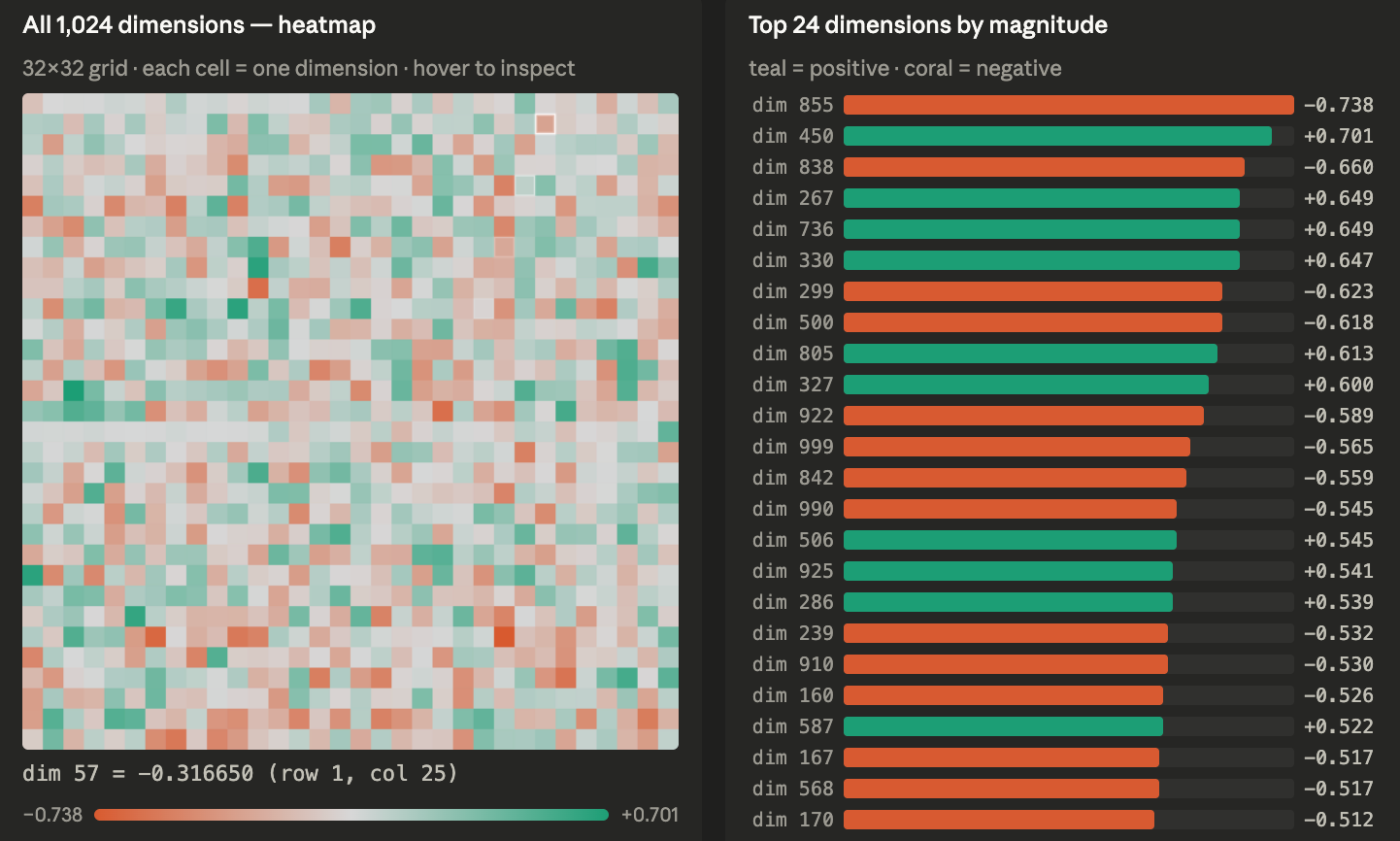
A vector is a quantity with a magnitude and direction. The NLLB-200 embedding table has 1024 columns, each representing a dimension. The dimension is a semantic space - a dimension of meaning (e.g. person, being, etc).
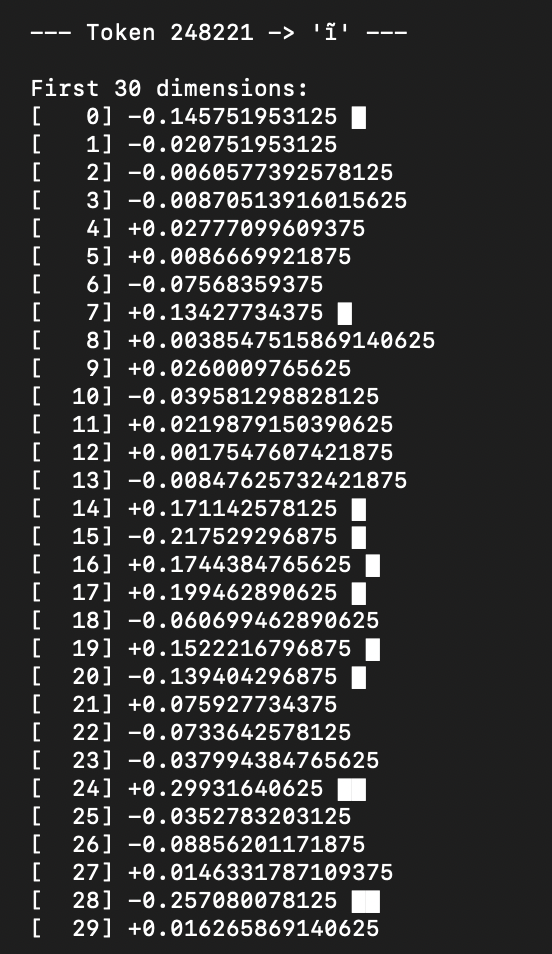
In this case, I focused on the Kikuyu diacritic ĩ, which can mean numerous things depending on the context, position in a word and the words it is paired with.
Result
I managed to trace the i token from the word "Mwarĩ", which had a dedicated token to represent the term. It was satisfying to visualise the 1,024 vectors across the semantic space, with a sorted list of the top 24 dimensions by magnitude.
Great as that was, it has opened up a greater itch: what meaning does each dimension encode?